Inleiding
Deze ‘bijsluiter’ is de gebruikershandleiding behorend bij de Handreiking Duurzaam Toegankelijke Algoritmes. Deze handreiking bestaat uit een overzichtsplaat, een vragenlijst en deze bijsluiter. Alle onderdelen van zowel de overzichtsplaat als de vragenlijst worden in dit document nader toegelicht en waar mogelijk voorzien van praktische voorbeelden.
Waarom deze handreiking?
De toepassing van kunstmatige intelligentie biedt overheden nieuwe mogelijkheden om op een slimme manier analyses uit te voeren en beslissingen te nemen. De afgelopen jaren zijn steeds meer overheidsinstellingen met dergelijke techniek aan de slag gegaan in de hoop de dienstverlening effectiever en efficiënter te maken.
Tegelijkertijd zijn er zorgen. De Raad van State waarschuwde eind 2018 voor het uithollen van burgerrechten als gevolg van een gebrek aan transparantie [Raad van State (2018)]. Minister voor Rechtsbescherming Sander Dekker beloofde na kamervragen om onderzoek te doen naar de transparantie van algoritmes [Sander Dekker (2018, 9 oktober)].
Tegen deze achtergrond is vanuit het KIA-kennisplatform Informatiehuishouding Overheden een werkgroep aan de slag gegaan rond de vraag: welke maatregelen kunnen we bij het ontwerpen van een algoritme treffen om deze duurzaam toegankelijk te maken. Simpel gesteld: hoe archiveren we een algoritme? Het antwoord op deze vraag is niet eenduidig, zoals ook de toepassing van algoritmes niet eenduidig is. Verschillende omstandigheden vragen om verschillende keuzes. Daarom is deze handreiking opgesteld, om te helpen bij het maken van dergelijke keuzes.
Voor wie is deze handreiking?
Deze handreiking is bedoeld voor medewerkers in het werkterrein informatiebeheer/ archivering, die als adviseur betrokken zijn bij het ontwerpen van een algoritme. Er wordt bij de lezer kennis verondersteld van wet- en regelgeving op het gebied van archivering en van gangbare principes en standaarden op het vlak van informatiebeheer en ‘archiving by design’.
Waar gaat deze handreiking niet over?
Deze handreiking richt zich enkel op het onderdeel informatiebeheer/archivering. Het biedt geen integrale handleiding voor het ontwikkelen van een algoritme, maar dient in samenhang gebruikt te worden met andere handreikingen die bijvoorbeeld specifiek gaan over privacy en ethiek.
Definities
In dit document worden de volgende definities gehanteerd.
Algoritme
Een algoritme is een eindige reeks instructies die vanuit een gegeven begintoestand naar een beoogd doel leidt.
Bron: https://nl.wikipedia.org/wiki/Algoritme (25122019).
Broncode
De programma-instructies die zijn geschreven door een programmeur, dit kan bijvoorbeeld in Python zijn.
Bron: https://www.woorden.org/woord/broncode
Data
Synoniem voor gegevens. Zie: gegeven.
Datamodel
Synoniem voor gegevensmodel. Zie: gegevensmodel.
Deep learning
Deep learning is een onderdeel van machine learning, gebaseerd op meerlaagse neurale netwerken.
Gegeven
De weergave van een feit, begrip of aanwijzing, geschikt voor overdracht, interpretatie of verwerking door een persoon of apparaat. Synoniem meervoud: data (gegevens).
Bron: https://archiefwiki.org/wiki/Gegeven (19122017)
Gegevensmodel
Het gegevensmodel beschrijft de manier waarop gegevens in een individuele database zijn opgeslagen.
Bron: https://nl.wikipedia.org/wiki/Datamodel (25122019)
Informatie
Betekenisvolle gegevens (data).
Bron: https://www.noraonline.nl/wiki/Informatie (19122017)
Kunstmatige intelligentie
Kunstmatige intelligentie (KI), of artificiële intelligentie (AI), zijn apparaten die reageren op data of impulsen uit hun omgeving, en op basis daarvan zelfstandig beslissingen nemen. Het gaat bij KI dus niet om de rekenkracht, maar om de mogelijkheid (zelfstandig) te leren en beslissingen te nemen. De apparaten zijn zich echter niet bewust van de taken die ze uitvoeren. Ze volgen algoritmes en herkennen patronen.
Bron: https://www.mediawijsheid.nl/kunstmatigeintelligentie/ (25122019)
Machine learning
Een computerprogramma wordt gezegd om te leren van ervaring E met betrekking tot een bepaalde taakklasse T en prestatiemaat P als zijn prestatie bij taken in T, zoals gemeten door P, verbetert met ervaring E. Dus als je wilt dat je programma voorspellingen maakt, bijvoorbeeld verkeerspatronen bij een drukke kruising (taak T), kun je het door een algoritme voor machine learning- uitvoeren met gegevens over historische verkeerspatronen (ervaring E) en, als het succesvol geleerd heeft, dan zal het beter presteren bij het voorspellen van toekomstige verkeerspatronen (prestatiemaat P).
Fase 1: Analyse - impactprofielen
1.1. Inleiding
De eerste stap bij het ontwerp van een algoritme, is het maken van een korte analyse over het doel en de toepassing. Hierbij horen vragen als: welk proces wordt door het algoritme ondersteund, en: wie worden geraakt door de inzet van het algoritme? Het resultaat van deze analyse is inzicht in het impactprofiel. Dit inzicht helpt bij het nemen van de juiste maatregelen op het gebied van archivering.
Algoritmes kunnen op vele wijzen worden ingezet en de potentiële impact kan daardoor per geval verschillen. Dit betekent dat de wijze waarop de archivering wordt ingericht ook per geval kan verschillen. Een bewaartermijn kan heel lang of juist heel kort zijn en informatie moet voor grote of juist voor kleine groepen mensen beschikbaar zijn. Om hier meer structuur in te bieden, is een viertal impactprofielen benoemd. Aan deze profielen zitten bepaalde kenmerken vast die helpen om de archivering ‘by design’ in te richten. Door in de analysefase een beeld te krijgen welk impactprofiel van toepassing is (let op: dit kunnen er meerdere tegelijk zijn), wordt duidelijker welke aandachtspunten van belang zijn bij de inrichting van de archivering. Dit helpt bij het vaststellen van een bewaartermijn of het maken van keuzes over het eventueel actief openbaar maken van informatie over het algoritme.
In deze paragraaf wordt uitgelegd welke impactprofielen er zijn en welke archiveringsuitgangspunten hieruit voortvloeien. Deze paragraaf geeft geen concreet antwoord op alle vragen, maar geeft wel richting.
1.2. Relevante wetgeving
Er is een aantal specifieke informatiewetten waaruit maatregelen volgen ten aanzien van de archivering. Deze zijn zonder meer allemaal in elk impactprofiel van toepassing, maar waar de focus ligt kan per impactprofiel verschillen.
Hieronder volgt een beknopt overzicht van deze wetten, met een toelichting wat vanuit archiefperspectief hun impact is.
- Archiefwet
Uit de Archiefwet komt voort dat er bewaartermijnen worden gehanteerd en dat informatie gedurende die bewaartermijnen toegankelijk zijn voor eenieder die rechtmatig toegang tot die informatie wenst. Informatie die is overgebracht naar een archiefbewaarplaats is op basis van de Archiefwet openbaar. Uit de Archiefwet volgt ook dat overheden een Selectielijst hanteren die de richtlijnen biedt voor bewaren en vernietigen. In de herziening van de Gemeentelijke Selectielijst in 2020, is bijvoorbeeld een expliciete richtlijn voor algoritmes opgenomen.
- AVG
Uit de AVG komt voort dat de privacy van natuurlijke personen beschermd moet worden. Dit betekent dat gegevens die tot een individu herleidbaar zijn, niet toegankelijk gemaakt mogen worden. Een maatregel is bijvoorbeeld dat bij overbrenging een beperking in openbaarheid op dergelijke gegevens wordt opgelegd.
- AWB
Uit de AWB komt voort dat een betrokkene bezwaar mag maken tegen een besluit die onder de AWB valt. In termen van archivering betekent dit dat een individuele beslissing herleidbaar moet zijn, als een algoritme wordt ingezet voor een proces waarop de AWB van toepassing is.
- WOB/WOO
In de huidige WOB is geregeld dat informatie, met inachtneming van de AVG, op verzoek beschikbaar gemaakt moet worden. Op dit moment is er een ontwerpwet, de WOO, die de WOB moet gaan vervangen. Het verschil is dat de WOB passieve openbaarheid regelt (iemand moet er eerst naar vragen) en dat de WOO van actieve openbaarheid uitgaat (overheden publiceren proactief informatie). Vanuit archiefperspectief betekenen deze wetten dat informatie op zo’n manier moet worden bewaard, dat deze (in geanonimiseerde vorm) eenvoudig beschikbaar gesteld kan worden.
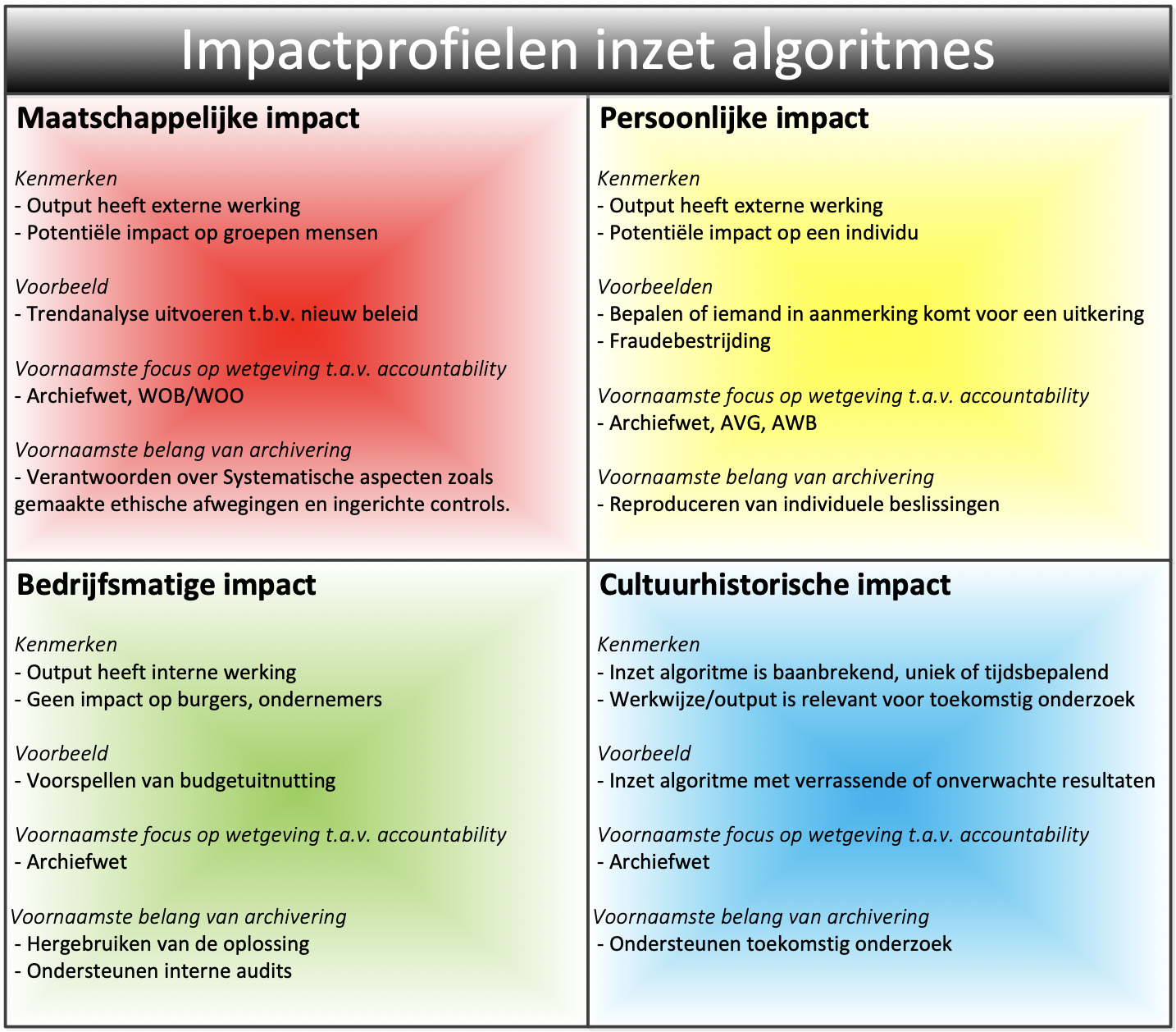
Afbeelding 1: Schematische weergave van de vier impactprofielen
1.3. Impactprofiel 1: Maatschappelijke impact
Het impactprofiel ‘maatschappelijke impact’ kenmerkt zich door in potentie groepen mensen te raken. Hierbij kun je bijvoorbeeld denken aan maatregelen in de openbare ruimte, zoals de keuze om in een bepaald gebied meer of minder toezicht uit te voeren of maatregelen die gericht zijn op het spreiden van verkeer om opstoppingen in een binnenstad te voorkomen.
De onderwerpen die door dit type toepassing geraakt worden, kunnen in potentie nieuwswaarde hebben en door de journalistiek worden opgemerkt. Daarom moet rekening worden gehouden met informatieverzoeken in het kader van de WOB/WOO. Dit betekent voor de archivering dat het belangrijk is om ontwerpdocumentatie goed vast te leggen, zodat de overheid in staat is om uit te leggen hoe het algoritme werkt, welke ethische afwegingen zijn gemaakt en op welke wijze is geborgd dat het algoritme functioneert zoals het bedoeld is.
De verantwoording is dus met name gericht op systematische aspecten. In dit profiel is de vuistregel daarom dat de ontwerpdocumentatie langer bewaard moet blijven dan de trainingsdata, de logica en de output. Ten behoeve van controleerbaarheid zullen ook de trainingsdata, de logica en de output enige tijd beschikbaar moeten blijven, maar het belang hiervan zal na verloop van tijd afnemen.
1.4. Impactprofiel 2: Persoonlijke impact
Het impactprofiel ‘persoonlijke impact’ kenmerkt zich door in potentie een individu te raken. Hierbij kun je bijvoorbeeld denken aan het maken van een inschatting of iemand recht heeft op een uitkering, een vergunning of een andere voorziening. Een ander voorbeeld is het maken van een keuze om bepaalde mensen onder verscherpt toezicht te stellen in het kader van bijvoorbeeld fraudebestrijding of terrorismebestrijding.
De onderwerpen die door dit type toepassing geraakt worden, kunnen in veel gevallen leiden tot een besluit die valt onder de AWB en waartegen een betrokkene derhalve bezwaar kan maken. Dit betekent voor de archivering dat het belangrijk is om de trainingsdata en de techniek goed vast te leggen, zodat de overheid in staat is om uit te leggen hoe een individuele beslissing tot stand is gekomen.
De verantwoording is dus met name gericht op reproduceren van individuele beslissingen. In dit profiel is de vuistregel daarom dat de bewaartermijn voor de trainingsdata, de logica en de output gekoppeld is aan die van het proces dat door het algoritme wordt ondersteund. In dit impactprofiel is privacybescherming van bijzonder belang, waardoor terughoudendheid betracht moet worden met informatieverstrekking in het kader van de WOB/WOO.
1.5. Impactprofiel 3: Bedrijfsmatige impact
Het impactprofiel ‘bedrijfsmatige impact’ kenmerkt zich door in potentie impact op de interne bedrijfsvoering te hebben, maar niet op de buitenwereld. Hierbij kun je bijvoorbeeld denken aan het doen van voorspellingen ten aanzien van overheidsuitgaven of het afstoten van huisvesting op basis van verwachte bezettingsgraad.
De onderwerpen die door dit type toepassing geraakt worden, zullen in de meeste gevallen niet de aandacht van de buitenwereld krijgen. Dit betekent voor de archivering dat het belangrijk is om de nadruk op de bedrijfsvoering te leggen. Informatie moet beschikbaar zijn voor interne audits, de logica en de ontwerpdocumentatie moet geborgd zijn ten behoeve van hergebruik.
De verantwoording is dus met name intern gericht en de impact op de samenleving is zeer beperkt. In dit profiel is de vuistregel daarom dat de ontwerpdocumentatie, trainingsdata, logica en output integraal worden bewaard met een doorgaans relatief korte bewaartermijn.
1.6. Impactprofiel 4: Cultuurhistorische impact
Het impactprofiel ‘cultuurhistorische impact’ kenmerkt zich door een unieke vorm van gebruik van een algoritme. Hierbij kun je bijvoorbeeld denken aan een algoritme dat tot hele onverwachte inzichten leidt of door een innovatieve toepassing van een algoritme. De toepassing van een algoritme kan ook cultuurhistorische impact hebben op basis van het inhoudelijke thema waarop het algoritme wordt ingezet, bijvoorbeeld een onderwerp dat veel in het nieuws is geweest.
De onderwerpen die door dit type toepassing geraakt worden, kunnen in veel gevallen relevant zijn voor toekomstig (historisch) onderzoek. Dit betekent voor de archivering dat één of meerdere componenten van het algoritme permanent bewaard moeten blijven en dat eisen aan duurzame toegankelijkheid voor de lange termijn van toepassing zijn.
De verantwoording is dus met name gericht op toekomstig onderzoek. In dit profiel is de vuistregel daarom dat in een vroegtijdig stadium afspraken gemaakt moeten worden met de beheerders van de archiefbewaarplaats, om de eisen die gesteld worden aan toekomstige overbrenging naar een archiefbewaarplaats mee te nemen in het ontwerp.
Fase 2: Ontwerp - vier componenten
2.1. Inleiding
Een algoritme bestaat uit een viertal componenten: trainingsdata, output, logica en documentatie. De archivering heeft betrekking op alle vier deze componenten. Bij het ontwerpen van het algoritme bekijk je dus per component hoe lang deze bewaard moet blijven, voor wie deze toegankelijk moet zijn en in welk vorm die wordt bewaard.
In deze paragraaf wordt elk van de vier componenten toegelicht.
2.2. Documentatie
Met documentatie wordt alle documentatie bedoeld die gaat over het ontwerp of de werking van het algoritme.
Er zijn drie soorten documentatie
- Ontwerpdocumentatie
- Dit is documentatie die tijdens de ontwerpfase wordt opgesteld en gezamenlijk het ontwerp vormen
- Beheerdocumentatie
- Dit is documentatie die tijdens de beheerfase wordt opgesteld over wijzigingen in het algoritme en over monitoring van de correcte werking van het algoritme
- Verantwoordingsdocumentatie
- Dit is documentatie die specifiek wordt opgesteld voor de uitlegbaarheid van een algoritme.
Ontwerpdocumentatie bestaat bijvoorbeeld uit een functioneel en technisch ontwerp of een privacyimpactanalyse. Beheerdocumentatie bestaat bijvoorbeeld uit verslagen van een Change Advisory Board.
Het is nodig om specifiek stil te staan bij verantwoordingsdocumentatie, want deze zal vaak op initiatief van de informatiebeheerdeskundige worden opgesteld. Het gaat hier om documentatie die vooral bedoeld is om de verantwoordingsfunctie van de overheid in te vullen. Een voorbeeld van dergelijke documentatie is een informatiewaardeanalyse. Als bij analyse van de trainingsdata bijvoorbeeld blijkt dat er subjectieve data wordt gebruikt (zie 2.3 Trainingsdata) dan kan daaruit de maatregel volgen dat er een analyse wordt opgesteld over de totstandkoming van deze gegevens: hoe functioneerde het proces waarin deze gegevens zijn verzameld? Hoe betrouwbaar zijn ze?
Ontwerpvragen die gaan over documentatie zijn bijvoorbeeld:
- Wat moet er minimaal worden beschreven om verantwoording te kunnen afleggen over de werking en het gebruik van het algoritme?
- Welke afspraken maken we over documenteren van het beheer?
2.3. Trainingsdata
Met ‘trainingsdata’ wordt bedoeld: de data waarmee het algoritme wordt gevoed. Dit wordt ook wel ‘de input’ genoemd.
De vorm van de trainingsdata kan verschillen. Een algoritme kan gebruik maken van een statische set data, die eenmalig worden verzameld en die in principe nooit meer wijzigen, denk aan een database met gegevens over verkeersongevallen gekoppeld aan geografische locaties in het jaar 2017. Er kan ook sprake zijn van realtime-data die enorm vluchtig is, denk bijvoorbeeld aan sensordata. In veel gevallen worden datasets eerst nog bewerkt, dan wordt bijvoorbeeld de datasemantiek genormaliseerd of worden datasets samengevoegd.
Verder kan de trainingsdata bestaan uit enerzijds trainingsdata op basis waarvan het algoritme patronen leert herkennen en anderzijds specifieke data die op basis van die patronen geanalyseerd worden.
Ook de inhoud van de trainingsdata kan verschillende vormen hebben. Data kunnen objectief en subjectief zijn. Een voorbeeld van objectieve data is het aantal inwoners per provincie: dit zijn neutrale feiten die niet ter discussie kunnen worden gesteld. Een voorbeeld van subjectieve data is een database met gegevens over belastingfraudeurs. In dit voorbeeld kan de vraag worden gesteld hoe deze gegevens zijn verzameld, hier zou bijvoorbeeld profilering aan de orde kunnen zijn. Het zijn geen neutrale feiten, maar gegevens die zijn verzameld op basis van beleidsmatige keuzes en menselijke inschatting.
Ontwerpvragen die te maken hebben met trainingsdata, zijn onder meer:
- Bewaren we trainingsdata of volstaan we met het bewaren van het datamodel (zie ook 2.5. Logica) en eventueel een beschrijving van welke brondata zijn gebruikt (zie ook 2.2. Documentatie)?
- Bewaren we alle ruwe data of alleen de bewerkte datasets?
- Als er realtime-data wordt gebruikt, bewaren we dan steekproeven om de werking van het algoritme achteraf te kunnen reproduceren?
2.4. Output
Met ‘output’ wordt bedoeld: de uitkomst van een algoritme. Hierin onderscheiden we drie verschillende vormen:
- Ruwe resultaten
- Dit zijn uitkomsten van een algoritmische berekening die niet door een mens zijn geïnterpreteerd. Bijvoorbeeld een Excel-rapport waarin sollicitanten op volgorde van geschiktheid worden gepresenteerd.
- Verwerkte resultaten
- Dit zijn documenten waaraan een algoritmische berekening ten grondslag ligt. Bijvoorbeeld een besluit om iemand wel of geen toelage te verstrekken of een beleidsdocument waarin algoritmische berekeningen zijn geanalyseerd en geduid.
- Weergave in dashboard
- Dit is een realtime-weergave op een bepaald moment in de tijd, die niet in een document wordt vastgelegd.
Ontwerpvragen die te maken hebben met output zijn bijvoorbeeld:
- Regelen we de archivering van de output op het niveau van de zaak waarop het betrekking heeft en zien we de archivering van de werking van het algoritme als een op zichzelf staande zaak of regelen we de archivering integraal?
- Als algoritmische berekeningen als realtime-weergave in een dashboard worden getoond, is het dan mogelijk om een export te maken op het moment van raadpleging zodat wordt vastgelegd welk inzicht op welk moment is gebruikt voor verdere verwerking? Wat is hier aanvullend op instructieniveau voor nodig?
2.5. Logica
De logica bestaat uit de code en het datamodel.
De code bestaat uit meerdere rekenregels die verbanden weergeven. Een voorbeeld: als een algoritme wordt ingezet om automatisch documenten te herkennen, dan wordt het algoritme eerst getraind door bijvoorbeeld heel veel verschillende facturen te laten zien. Het algoritme zoekt dan naar gedeelde eigenschappen en legt deze vast in rekenregels, zoals: ‘als er bovenaan het document rekening of factuur staat, dan is het waarschijnlijk een factuur’. Hoe meer trainingsdata een algoritme verwerkt, hoe meer verbanden het zal herkennen en hoe uitgebreider de code wordt. Vanwege dit zelflerende karakter, is het vaak nodig om periodiek te toetsen of het algoritme nog naar behoren werkt.
Het datamodel definieert de data waarmee een algoritme wordt gevoed. Dit kun je vergelijken met een Excel-sheet: alle gegevens in kolom A staan voor leeftijd, alle gegevens in kolom B staan voor geslacht. Als er meerdere datasets worden gebruikt, dan maakt het datamodel duidelijk dat op kolom A in dataset 1 dezelfde definitie van toepassing is als op kolom D in dataset 2. Zo weet het algoritme dat het appels met appels vergelijkt en peren met peren. Het datamodel is dus een essentieel element in het algoritme: daarin wordt vastgelegd welke type gegevens worden gebruikt en wat de inhoudelijke betekenis is van die gegevens.
Een voorbeeld. Bij een sollicitatieproces voor stewardessen wordt op basis van een algoritme een lijst opgesteld met de meest geschikte kandidaten. Telkens als er iemand wordt aangenomen, leert het algoritme daar weer van. Omdat in deze specifieke sector meer vrouwelijke dan mannelijke kandidaten beschikbaar zijn, worden er vaker vrouwen dan mannen aangenomen. Het algoritme kijkt niet naar oorzaken, maar enkel naar verbanden. Het gevolg is dat het algoritme mannelijke kandidaten structureel lager scoort. Bij een audit op het algoritme komt dit als onwenselijk, discriminerend gedrag naar boven en het datamodel wordt hierop aangepast, zodat het algoritme het element ‘geslacht’ voortaan niet meer meeneemt in de analyse.
Ontwerpvragen die te maken hebben met logica zijn bijvoorbeeld:
- Welke afspraken maken we over het documenteren van de monitoring van de correcte werking van het algoritme?
- Met welke frequentie archiveren we de code? Bij elke wijziging, bij elke majeure wijziging of periodiek?
- Hoe leggen we de keuzes vast aan de hand waarvan het datamodel tot stand is gekomen?
- Hoe documenteren we eventuele wijzigingen in het datamodel?
Fase 3: Beheer - de beheerprocessen
3.1 Inleiding
Informatiebeheer kent een aantal beheerprocessen bij de duurzame toegankelijkheid van algoritmes.
3.2 Vernietigen
Het vernietigingsproces staat niet gelijk aan het bepalen en toekennen van bewaartermijnen. Het gaat over het operationaliseren van de vernietiging. Vernietigen is een proces met een aantal mogelijke processtappen:
- Opstellen vernietigingslijst, handmatig of geautomatiseerd
- Controleren van vernietigingslijst
- Accorderen vernietigingslijst
- Opstellen aanvraag Machtiging (Lokale Overheden)
- Indienen aanvraag Machtiging (Lokale Overheden)
- Verstrekken Machtiging (Lokale Overheden)
- Opdracht geven tot vernietiging
- Uitvoeren daadwerkelijke vernietiging (handmatig of geautomatiseerd)
- Opstellen verklaring van vernietiging
NB. Bij het rijk is een machtiging van vernietiging niet nodig. Bij de lokale overheden wel, daar kun je overwegen een doorlopende machtiging aan te vragen. De stappen van de machtiging vervallen in deze gevallen.
Aan de processtappen moet je actoren koppelen en de verantwoordelijkheid in de organisatie te beleggen. Tenslotte beschrijf je de mate van automatisering. De processtappen en de mate van automatisering kunnen verschillen, afhankelijk van de informatie; Stel dat datasets eerst als ruwe data worden verzameld en daarna worden getransformeerd, samengevoegd, geaggregeerd en/of geanonimiseerd of gepseudonimiseerd voordat ze aan het algoritme worden gevoed. Bij elke bewerking ontstaat in technische zin een nieuw databestand. Je kan voor de ‘halffabrikaten’ een kortere bewaartermijn hanteren dan voor de ‘eindproducten’ en om de vernietiging daarvan te automatiseren, terwijl je voor de eindproducten wellicht meer controlestappen en handmatige acties in wil bouwen. Het is bijvoorbeeld goed denkbaar om voor sommige ‘halffabrikaten’ geen vernietigingslijst ter goedkeuring aan een beslisser voor te leggen, maar in plaats daarvan eenmalig het ontwerp te laten goedkeuren.
3.3 Overbrengen
Overbrengen is als proces heel vergelijkbaar met het vernietigingsproces. De stappen zijn vergelijkbaar, enkel moet er bij overbrenging met de beheerder van de archiefbewaarplaats worden samengewerkt. Deze stelt bepaalde eisen aan de wijze van overbrenging. Net als bij een doorlopende machtiging kun je afspraken maken met de beheerder zodat niet elke overbrenging apart behandeld wordt, maar het een sterk geautomatiseerd proces is. De stappen kunnen bijvoorbeeld zijn:
- Opstellen lijst voor overbrenging
- Controleren van de lijst
- Afstemmen met Beheerder over de lijst tot overbrenging
- Accorderen lijst voor overbrenging
- Opdracht geven tot overbrenging
- Uitvoeren overbrenging
- Akkoord/ bevestiging overbrenging (door beheerder)
Ook hiervoor geldt dat het van belang is om de rollen vooraf te definiëren, in samenspraak met de beheerder van de archiefbewaarplaats.
Als datasets voor eeuwigdurende bewaring in aanmerking komen, dan is het zinvol om al in de ontwerpfase na te denken over overbrenging naar een archiefbewaarplaats. Hier zijn verschillende keuzes voor de overbrenging:
- eerst verzamelen en na X jaar een gehele collectie overbrengen,
- als doorlopend proces aan het eind van het kalenderjaar de relevante documenten overbrengen
- Als een doorlopend proces na afsluiting overbrengen (dit kan dus meerdere malen dagelijks zijn)
Voor sommige trainingsdata is de eeuwigdurende bewaring vanuit de bron al geregeld.
3.4 Beschikbaarstellen
Beschikbaarstellen doe je in eerste instantie voor direct betrokkenen, de vraag is daarbij wel hoe je dit vorm geeft. Dit moet je vaststellen. Wil je een dashboard gebruiken, een ruwe dataset, de beslissingen en/of de opgestelde documenten.
Van belang is het in beeld brengen van de verschillende gebruikersgroepen en hun informatiebehoeften. Daarop kan dan ook de beschikbaarstelling worden afgestemd. Dit kan voor verschillende groepen ook verschillende toegangen en zicht op de informatie betekenen.
Hierbij moet je autorisatie en eventuele beperkingen op de toegang vaststellen en implementeren. En vergeet daarbij ook niet om controles op ongeautoriseerde toegang, handmatig of geautomatiseerd uit te voeren.
Van belang daarbij is om op basis van de gebruikte data vast te stellen welke openbaarheidsregime van toepassing is, de WOO, AVG of Archiefwet (enkel na overbrenging)
Mogelijk is het nodig om specifieke activiteiten te beleggen ten aanzien van beschikbaarstelling van informatie aan derden. Bijvoorbeeld het anonimiseren van datasets voorafgaand aan publicatie. Ook het gebruik van een algoritmeregister waarin is vastgelegd uit welke bronnen trainingsdata afkomstig is, kan bijdragen aan transparantie. Voorts kan gedacht worden aan het aanwijzen van een contactpersoon die door derden benaderd kan worden voor vragen.
3.5 Documenteren
In de beheerfase kunnen er situaties ontstaan die gedocumenteerd moeten worden om accountability te kunnen blijven afleggen. Het beheerproces ‘documenteren’ borgt dat de impact van veranderingen wordt vastgelegd, dit zal vanuit het wijzigingenproces georganiseerd moeten worden.
3.5.1 Gedragsmonitoring
Het is niet altijd duidelijk hoe een algoritme tot een bepaald inzicht komt. Zeker wanneer een algoritme zichzelf ontwikkelt. Daarom is het zinvol om periodiek te toetsen of het algoritme nog het gedrag vertoont waar het ooit voor ontworpen is en eventuele afwijkingen op dat punt te corrigeren.
3.5.2 Scopewijzigingen
Als een algoritme dat ooit voor een bepaald doel is ontworpen later wordt ingezet voor een ander doel, dan zal voor het nieuwe doel een deel van het ontwerpproces opnieuw moeten worden uitgevoerd. Mogelijk zijn er nu bijvoorbeeld andere bewaartermijnen aan de orde.
3.5.3 Aanvullingen
Wanneer nieuwe databronnen worden aangewend om het algoritme te voeden, dan verdient het aanbeveling om opnieuw te kijken naar het onderdeel ‘trainingsdata’ in de vragenlijst van deze handreiking.
4. De vragenlijst
4.1 Inleiding
In deze paragraaf worden de vragen uit de vragenlijst toegelicht. Je leest wat de achterliggende gedachte van elke vraag is en waar mogelijk geven we voorbeelden van mogelijke beantwoording. De vragenlijst is bedoeld als checklist voor de informatiebeheerspecialist. De vragenlijst helpt om te voorkomen dat aspecten van duurzame toegankelijkheid en accountability over het hoofd worden gezien. De bedoeling van de vragenlijst is dat de informatiebeheerspecialist probeert om de vragen zelf, eventueel samen met andere betrokkenen, te beantwoorden en zo vanuit de eigen expertise een bijdrage te leveren aan het ontwerp van een algoritme. De vragenlijst dient zodoende als handvat om archiveringsprincipes ‘by design’ onderdeel te maken van de inrichting. Niet alle vragen zullen altijd relevant zijn, bovendien zullen er ongetwijfeld vragen ontbreken. Het doel is om de lezer op weg te helpen bij het uitvoeren van analyses die ten grondslag liggen aan te maken ontwerpkeuzes op het gebied van archivering.
4.2 Analysefase
In de analysefase, zijn de volgende vragen aan de orde.
4.2.1 Welk proces wordt ondersteund door het algoritme?
Deze vraag gaat over het beoogde doel van de inzet van het algoritme. Het is belangrijk om te weten waarvoor een algoritme wordt ingezet, omdat aan de hand van die kennis ingeschat kan worden welke specifieke risico’s zich voordoen en met welke belanghebbenden rekening gehouden moet worden. Ook kan aan de hand van deze informatie worden bekeken welk zaaktype en welke bewaartermijn(en) uit de selectielijst van toepassing zijn.
Op welke wijze wordt het algoritme ingezet?
Een algoritme kan op verschillende wijzen worden ingezet. Bijvoorbeeld voor een eenmalige analyse of juist voor een periodiek of doorlopend gebruik. Dit onderscheid kan van belang zijn bij het bepalen van de beheermaatregelen. Bij periodiek of doorlopend gebruik, zal bijvoorbeeld gekeken moeten worden of trainingsdata wordt geactualiseerd en wat dat eventueel betekent voor versiebeheer, waar dat bij eenmalige toepassing niet van belang zal zijn.
Een ander aspect dat bij deze vraag hoort, is de vraag of de inzet van het algoritme tot volledig geautomatiseerde analyse en/of besluitvorming leidt, of dat de uitkomst van een algoritme input is voor verder menselijk handelen. Dit is relevant om te weten omdat bij volledige automatisering andere maatregelen horen ten aanzien van accountability dan wanneer er menselijk handelen bij komt kijken om de resultaten verder te interpreteren en verwerken.
Wat is de mogelijke impact van het algoritme?
Aan de hand van de vorige vragen, kan een eerste inschatting worden gemaakt van welk impactprofiel van toepassing is. Zie paragraaf 2 waarin de impactprofielen zijn beschreven. Het bepalen van het impactprofiel helpt om in de volgende fasen de juiste maatregelen te bepalen.
4.3 Ontwerpfase - documentatie
In de ontwerpfasen komen er vragen aan bod per component (zie de uitleg in paragraaf 3). Deels zijn die vragen generiek, dus voor elk component hetzelfde, deels zijn ze componentgebonden. In deze subparagraaf worden de vragen toegelicht op het component ‘documentatie’.
4.3.1 Wat? – Welke inhoudelijke informatie is van belang om te bewaren?
Het doel van deze vraag is om stil te staan bij welke type informatie belangrijk is om vast te leggen en te bewaren. Met dat inzicht kan vervolgens worden gekeken in hoeverre deze informatie wordt beschreven in de documentatie die toch al opgesteld zou worden en in hoeverre er wellicht nog aanvullende documentatie gemaakt moet worden om de verantwoordingsfunctie in te vullen.
Voorbeelden van informatie die mogelijk van belang is om vast te leggen en te bewaren, zijn:
- Welke ethische vraagstukken zijn gedurende het project aan de orde geweest?
- Wat is de inhoudelijke waarde van de data?
- Wat is de kwaliteit van de data?
- Welke betrokkenen zijn/kunnen potentieel getroffen worden door de inzet van het algoritme (zie bijsluiter)?
- Welke risico’s zijn geïdentificeerd?
- Welke risicomitigerende maatregelen zijn getroffen?
- Welke business case is van toepassing?
4.3.2 Wat? – Welke documenten zijn/worden er vanuit het document opgesteld?
Bij de vorige vraag is in kaart gebracht welke informatie van belang is om vast te leggen. Het doel van deze vraag is om in kaart te brengen welke documentatie al is of wordt opgesteld. Vervolgens kan worden gekeken in welke mate daarmee de behoefte die uit de vorige vraag blijkt al wordt afgedekt.
Voorbeelden van veel voorkomende documentatie zijn:
- business case
- projectarchitectuur
- privacy impactanalyse
- risicoanalyse
- functioneel/technisch ontwerp
- beheerplan
4.3.3 Wat? – Zijn de ontwerpkeuzes voldoende expliciet uitgewerkt t.b.v. verantwoording?
Deze checkvraag dient om scherp te krijgen of de beschrijvingen in de documentatie voldoende compleet en duidelijk zijn. Ten behoeve van de verantwoording van het overheidshandelen is het bijvoorbeeld prettig als een tekst voor een buitenstaander begrijpelijk is en bijvoorbeeld niet vol staat met niet toegelichte afkortingen die alleen binnen de eigen organisatie gangbaar zijn. Ook is de vraag of de documentatie voldoende diepgang kent of alleen op abstract niveau een beschrijving geeft.
Een uitkomst kan zijn dat de ontwerpkeuzes voldoende uitlegbaar zijn vastgelegd, maar een uitkomst kan ook zijn dat dit onvoldoende het geval is. Dat kan leiden tot de maatregel om de bestaande documentatie hierop aan te passen ofwel om extra documentatie toe te voegen.
4.3.4 Hoe lang? – Hoe lang is het zinvol/nodig om de documentatie te bewaren?
De vraag hoe lang documentatie bewaard blijft, kan op verschillende manieren worden beantwoord. De keuze kan worden gemaakt om alle documentatie als een integraal geheel te zien en daar op basis van de selectielijst één bewaartermijn voor te hanteren. Een keuze kan ook zijn om dat per document te bekijken. Deze afweging hangt samen met de conclusies die zijn getrokken aan de hand van de vragen in de analysefase.
4.3.5 Waar? – Welke beschikbare opslaglocatie is het meest geschikt om de documentatie te bewaren?
In de ontwerpfase zal ook worden bepaald op welke locatie de bewaring van documenten plaatsvindt. De keuze voor een opslaglocatie is in sterke mate afhankelijk van interne richtlijnen over archivering en, indien van toepassing, publicatie. Als het beleid is om bepaalde informatie actief openbaar te maken dan zal deze informatie immers opgeslagen moeten worden op een plek van waaruit die publicatie mogelijk is. Een andere afweging is bijvoorbeeld of een organisatie een aangewezen archiefapplicatie heeft zoals een DMS of bijvoorbeeld een specialistische applicatie die aan een zoekmachine is gekoppeld waardoor de informatie vindbaar is voor interne belanghebbenden.
4.3.6 Vorm? – In welke vorm wordt de documentatie opgesteld?
Met oog op digitale duurzaamheid, is het nuttig om te inventariseren in welke vorm documentatie wordt opgesteld. Worden er documenten gecreëerd en, zo ja, welke bestandsformaten hebben die? Wordt er een centraal register bijgehouden in een gespecialiseerde applicatie? De volgende vragen die te maken hebben met vorm, zijn verdiepingsvragen waarvoor het nodig is om deze vraag eerst te beantwoorden.
4.3.7 Vorm? – Is de documentatie voor alle betrokkenen zonder specifieke tools/viewers raadpleegbaar?
Als informatie in een vorm wordt vastgelegd die niet goed toegankelijk is voor (potentiële) belanghebbenden, dan is dat een aandachtspunt.
4.3.8 Vorm? - Indien er een lange bewaartermijn is: zijn de gebruikte bestandsformaten geschikt voor langere bewaring?
Voor documenten die op enig moment moeten worden overgebracht naar een archiefbewaarplaats gelden mogelijk eisen ten aanzien van duurzame bestandsformaten. Waar mogelijk, is het handig om deze documenten direct vanaf creatie in een geschikt formaat op te slaan.
4.3.9 Beschikbaarstelling? - Wie zijn belanghebbenden van de documentatie (primaire en secundaire gebruikers, ook op de lange termijn)?
Voor de beschikbaarstelling is het van belang om te weten hoe belanghebbenden zoeken naar informatie en in welke vorm ze die tot zich willen nemen, zodat ze op geschikte wijze kunnen worden gepresenteerd. Er kunnen verschillende belanghebbenden zijn die op enig moment toegang tot de data nodig hebben. Dit kunnen interne medewerkers zijn die werken met het algoritme, maar ook bijvoorbeeld auditors. Daarnaast kan het gaan om externen, zoals rechtzoekende burgers.
4.3.10 Beschikbaarstelling? - Welk openbaarheidsregime is van toepassing?
Bij het beschikbaar stellen van documentatie is het van belang om relevante wet- en regelgeving (bv. WOO / WOB, AVG etc.)in acht te nemen en op basis daarvan autorisatie in te richten.
4.3.11 Beschikbaarstelling? - In welke vorm moet de documentatie beschikbaar gesteld worden aan belanghebbenden (bv. open data)?
Verschillende belanghebbenden willen informatie op verschillende wijzen gebruiken. Dat kan betekenen dat informatie op verschillende manieren ontsloten en gepresenteerd kan worden. Bijvoorbeeld een vorm voor interne kennisdeling die afwijkt van een vorm voor externe publicatie.
4.3.12 Beheer? - Hoe ziet het vernietigingsproces eruit?
Het ontwerpen van een vernietigingsproces gaat verder dan enkel het vaststellen van bewaartermijnen. Het gaat over het operationaliseren van de vernietiging door de processtappen te benoemen, daar actoren aan te koppelen en de verantwoordelijkheid in de organisatie te beleggen. Ook de controlemaatregelen (zoals beoordelen van een vernietigingslijst) en de mate van automatisering worden hierin meegenomen.
4.3.13 Beheer? - Hoe ziet het overbrengingsproces eruit?
Als documenten voor eeuwigdurende bewaring in aanmerking komen, dan is het zinvol om al in de ontwerpfase na te denken over overbrenging naar een archiefbewaarplaats. Richt je dit bijvoorbeeld traditioneel in: eerst verzamelen en na X jaar een gehele collectie overbrengen, via vervroegde overbrenging: bijvoorbeeld als doorlopend proces aan het eind van het kalenderjaar de relevante documenten overbrengen? De bijbehorende procesafspraken en verantwoordelijkheden kunnen aan de hand van deze keuze worden bepaald en belegd. Het is bij deze stap belangrijk om af te stemmen met de beheerder van de archiefbewaarplaats.
4.3.14 Beheer? - Hoe is in het wijzigingenproces geborgd dat de mogelijke impact van wijzigingen op het archiefregime wordt beoordeeld?
Als het gebruik van het algoritme significant wijzigt, dan kan dat betekenen dat de eerder bedachte maatregelen ten aanzien van archivering moeten worden herzien. Daarom is het van belang om in het wijzigingenproces op te nemen dat er een impactanalyse voor wijzigingen wordt uitgevoerd waarin ook naar dit aspect gekeken wordt.
4.3.15 Beheer? - Zijn er specifieke activiteiten te benoemen m.b.t. beschikbaarstelling aan derden (bv. bij Wob-verzoeken)?
Mogelijk is het nodig om specifieke activiteiten te benoemen en te beleggen ten aanzien van beschikbaarstelling van informatie aan derden. Bijvoorbeeld het anonimiseren van documenten voorafgaand aan publicatie. Ook het in de eigen organisatie kenbaar maken (bijvoorbeeld bij een Wob-functionaris) welke informatie er is en hoe die gevonden kan worden, draagt bij aan transparantie. Voorts kan gedacht worden aan het aanwijzen van een contactpersoon die door derden benaderd kan worden voor vragen.
4.4 Ontwerpfase - Trainingsdata
In de ontwerpfasen komen er vragen aan bod per component (zie de uitleg in paragraaf 3). Deels zijn die vragen generiek, dus voor elk component hetzelfde, deels zijn ze componentgebonden. In deze subparagraaf worden de vragen toegelicht op het component ‘trainingsdata’. In sommige gevallen is het wellicht niet eens nodig om trainingsdata te archiveren omdat bijvoorbeeld de documentatie voldoende informatie biedt om aan accountability-eisen te kunnen voldoen, in dergelijke gevallen is het uiteraard niet nodig om op detailniveau deze verdiepingsvragen te doorlopen.
4.4.1 Wat - Van welke bronnen maakt het algoritme gebruik (dataverzamelingen)?
Om de juiste maatregelen te kunnen bepalen, is het allereerst van belang om te weten uit welke informatiebronnen er wordt geput: waar komt de data vandaan, wie is de bronhouder, met welk doel is de data verzameld etcetera? Vervolgens kan, aan de hand van de volgende vragen, een nadere analyse worden gemaakt.
4.4.2 Wat - Wat is de aard van de data?
Deze vraag gaat over de vorm van de data. Is sprake van statische data (data die nooit meer wijzigt) of kan een dataset na verloop van tijd wijzigen? Dit is van belang om te weten of bijvoorbeeld versiebeheer een rol speelt bij de archivering. Verschillende vormen kunnen zijn:
- Statische data (een definitieve dataset die nooit meer wordt aangevuld of gewijzigd - bijvoorbeeld een database met geografische locaties van bomaanslagen tijdens de Tweede Wereldoorlog);
- Cumulatieve data (een dataset die wel wordt aangevuld, maar waarvan de data nooit meer wijzigen - bijvoorbeeld een database met de namen van alle presidenten van de Verenigde Staten);
- Dynamische data (een ‘levende’ dataset waarvan gegevens kunnen wijzigen - bijvoorbeeld een database waarin de vigerende bestemmingen van panden zijn vastgelegd);
- Realtime data (data die een situatie op een bepaald moment weergeven - bijvoorbeeld huidige sensordata).
4.4.3 Wat? - Zijn de data objectief of is er een mate van subjectiviteit?
In het kader van accountability, is één van de belangrijkste aspecten dat duidelijk wordt gemaakt dat en hoe vooringenomenheid (bias) in trainingsdata leidt tot geautomatiseerde willekeur, profilering en/of geautomatiseerde discriminatie. Daarom is het belangrijk om van trainingsdata vast te stellen of die objectief of subjectief is. Objectieve data wil zeggen: harde feiten die niet ter discussie staan, bijvoorbeeld het aantal huizen in een woonwijk op een bepaald moment in de tijd. Daar staan subjectieve data tegenover: data waarbij (bewust of onbewust) keuzes zijn gemaakt die invloed hebben op de content van een dataset. Bijvoorbeeld gegevens over fraudeplegers: hierbij is het belangrijk om te beseffen dat er enkel gegevens bestaan over gepakte fraudeplegers, waarbij beleidskeuzes ten aanzien van opsporing en detectie een rol kunnen hebben gespeeld. Dat brengt het risico van profilering met zich mee. Om volledig accountable te kunnen zijn, is het daarom gewenst om te weten hoe het proces heeft gefunctioneerd waarbinnen de data gecreëerd of verzameld zijn.
Voor de archivering geldt dat het logisch is om zwaardere maatregelen te treffen voor subjectieve data dan voor objectieve data. Voor objectieve data volstaat wellicht een beschrijving van een dataset, terwijl voor subjectieve data ook bekend zal moeten zijn welke risico’s het gebruik van deze data met zich meebrengt en welke mitigerende maatregelen zijn getroffen zodat hierover verantwoording kan worden afgelegd. Er kan natuurlijk ook voor worden gekozen om aan de hand van deze analyse bepaalde data niet aan het algoritme te voeden.
4.4.4 Wat? - Wat is de kwaliteit van de data?
Om rekenschap te kunnen geven over de betrouwbaarheid van informatie die met een algoritmische toepassing is gecreëerd, is het van belang om inzicht te hebben in de kwaliteit van de gebruikte trainingsdata. Simpel gezegd: slechte data vergroten de kans op het nemen van slechte besluiten. Andersom geldt hetzelfde: als de kwaliteit goed is, draagt dat bij aan het nemen van betere beslissingen.
Kwaliteit is een ruim begrip. Wat verstaan we daar onder? Een aantal aspecten waar je aan kunt denken, zijn:
- Semantiek: Consistentie in semantiek kan worden gemeten door bijvoorbeeld te kijken of in de bron gebruik wordt gemaakt van basis- en kernregistraties, woordenboeken en gecontroleerde tabellen. Als data in de bron wordt gecreëerd met vrijetekstvelden, dan is de consistentie waarschijnlijk laag. Een algoritme kan bijvoorbeeld denken dat ‘PC Hooftstraat’ en ‘Pieter Cornelisz Hooftstraat’ twee verschillende straten zijn;
- Periode: Hoe ver terug gaan de data? Zijn er alleen data beschikbaar van afgelopen week, of is er over een langdurige periode data verzameld? In algemene zin geldt dat een algoritme betrouwbaarder wordt naarmate er meer data wordt verwerkt zodat er meer patronen ontdekt kunnen worden;
- Volledigheid: Zijn de data in de bron consequent bijgehouden of zijn er hiaten?
- Aanwezigheid persoonsgegevens: Zijn de data geanonimiseerd of gepseundonimiseerd?
4.4.5 Wat? - Wordt in de beheerfase data toegevoegd, vervangen of blijven deze onveranderd?
Als de data uit de bron één op één wordt gebruikt en de archivering in de bron goed is geregeld, dan is het - mits de bewaartermijnen niet afwijken - niet direct nodig om deze trainingsdata apart te archiveren in het kader van de algoritmische toepassing. Als er een verdere bewerking of verrijking plaatsvindt, dan is de data die in de bron aanwezig is mogelijk niet meer genoeg om een beslissing die met een algoritme is genomen te kunnen reproduceren.
4.4.6 Hoe lang? - Welk impactprofiel is van toepassing?
In de ontwerpfase is deze vraag van belang om te bepalen wat de juiste te treffen maatregelen zijn n.a.v. het gebruik van de trainingsdata. Deze afweging kun je maken o.b.v. selectielijst(en). In paragraaf 2 zijn de impactprofielen afzonderlijk beschreven. Of het bewaren van trainingsdata zinvol is, of wellicht kan worden volstaan met het bewaren van documentatie, hangt mede af van welk impactprofiel van toepassing is.
4.4.7 Hoe lang? - Indien er regelmatig nieuwe versies worden gevoed aan het algoritme, is het dan zinvol om alle versies te bewaren of kan worden volstaan met een beperkt aantal?
Als er regelmatig nieuwe versies van trainingsdatasets worden geleverd, dan kan dat de werking van het algoritme beïnvloeden. Daarom is het zinvol om na te denken welke versies bewaard moeten blijven: bijvoorbeeld alle versies, alleen de meest recente versie of een representatieve steekproef. Dit is mede afhankelijk van hoe groot de verschillen zijn: gaat het bijvoorbeeld enkel om cumulatieve aanvullingen of wordt de data inhoudelijk gewijzigd (zie ook 4.4.2.)?
4.4.8 Waar? - Is het archiefregime in de bron voldoende?
Trainingsdata komt uit een bron. Indien de archivering in die bron dusdanig is geregeld dat de trainingsdata daar beschikbaar is gedurende de bewaartermijn die voortvloeit uit de algoritmische toepassing, dan hoeft de trainingsdata niet apart gearchiveerd te worden. Immers: voor reconstructie kan dan te allen tijde terug worden gegrepen op de bron.
Indien dit niet het geval is, zijn er twee opties. Ofwel het aanpassen van het archiefregime in de bron ofwel het opzetten van een eigen archiefregime.
4.4.9 Vorm? - In welke vorm wordt de data uit de bron aangeleverd?
De levering vanuit de bron kan op verschillende manieren plaatsvinden. Bijvoorbeeld:
- Real-time (bv. via API);
- Periodiek (bv. via datadumps op basis van een script);
- Eenmalige extractie.
Als het algoritme rechtstreeks de bron bevraagt, vindt er geen lokale opslag plaats. Als data eerst worden verzameld op een specifieke locatie waar het algoritme toegang toe heeft, dan geldt dat niet. Als er ergens data wordt opgeslagen, dan zal er dus ook nagedacht moeten worden over bewaartermijnen, versiebeheer en opschoning.
4.4.10 Beschikbaarstelling? - Wie zijn belanghebbenden van de data (primaire en secundaire gebruikers, ook op de lange termijn)?
Voor de beschikbaarstelling is het van belang om te weten hoe belanghebbenden zoeken naar informatie en in welke vorm ze die tot zich willen nemen, zodat ze op geschikte wijze kunnen worden gepresenteerd. Er kunnen verschillende belanghebbenden zijn die op enig moment toegang tot de data nodig hebben. Dit kunnen interne medewerkers zijn die werken met het algoritme, maar ook bijvoorbeeld auditors. Daarnaast kan het gaan om externen, zoals rechtzoekende burgers.
4.4.11 Beschikbaarstelling - Welk openbaarheidsregime is van toepassing?
Bij het beschikbaar stellen van documentatie is het van belang om relevante wet- en regelgeving (bv. WOO / WOB, AVG) in acht te nemen en op basis daarvan autorisatie in te richten.
4.4.12 Beschikbaarstelling - In welke vorm moet de data beschikbaar gesteld worden voor belanghebbenden (bv. open data)?
Verschillende belanghebbenden willen informatie op verschillende wijzen gebruiken. Dat kan betekenen dat informatie op verschillende manieren ontsloten en gepresenteerd kan worden. Bijvoorbeeld door een dataset als geanonimiseerd .csv-bestand te publiceren, of door gegevens rechtstreeks vanuit de bron via een API beschikbaar te stellen.
4.4.13 Beheer - Hoe ziet het vernietigingsproces eruit?
Het ontwerpen van een vernietigingsproces gaat verder dan enkel het vaststellen van bewaartermijnen. Het gaat over het operationaliseren van de vernietiging door de processtappen te benoemen, daar actoren aan te koppelen en de verantwoordelijkheid in de organisatie te beleggen. Ook de controlemaatregelen (zoals beoordelen van een vernietigingslijst) en de mate van automatisering worden hierin meegenomen.
Het zou kunnen dat datasets eerst als ruwe data worden verzameld en daarna worden getransformeerd, samengevoegd, geaggregeerd en/of geanonimiseerd of gepseudonimiseerd voordat ze aan het algoritme worden gevoed. Bij elke bewerking ontstaat in technische zin een nieuw databestand. Je zou kunnen overwegen om voor de ‘halffabrikaten’ een kortere bewaartermijn te hanteren dan voor de ‘eindproducten’ en om de vernietiging daarvan op basis van een script te automatiseren, terwijl je voor de eindproducten wellicht meer controlestappen in wil bouwen.
4.4.14 Beheer - Hoe ziet het overbrengingsproces eruit?
Als datasets voor eeuwigdurende bewaring in aanmerking komen, dan is het zinvol om al in de ontwerpfase na te denken over overbrenging naar een archiefbewaarplaats. Richt je dit bijvoorbeeld traditioneel in: eerst verzamelen en na X jaar een gehele collectie overbrengen, via vervroegde overbrenging: bijvoorbeeld als doorlopend proces aan het eind van het kalenderjaar de relevante documenten overbrengen? De bijbehorende procesafspraken en verantwoordelijkheden kunnen aan de hand van deze keuze worden bepaald en belegd. Het is bij deze stap belangrijk om af te stemmen met de beheerder van de archiefbewaarplaats.
4.4.15 Beheer - Hoe is in het wijzigingenproces geborgd dat de mogelijke impact van wijzigingen op het archiefregime wordt beoordeeld?
Als het gebruik van het algoritme significant wijzigt en/of als er andere bronnen worden toegevoegd, dan kan dat betekenen dat de eerder bedachte maatregelen ten aanzien van archivering moeten worden herzien. Daarom is het van belang om in het wijzigingenproces op te nemen dat er een impactanalyse voor wijzigingen wordt uitgevoerd waarin ook naar dit aspect gekeken wordt.
4.4.16 Beheer - Zijn er specifieke activiteiten te benoemen m.b.t. beschikbaarstelling aan derden (bv. bij WOB-verzoeken)?
Mogelijk is het nodig om specifieke activiteiten te benoemen en te beleggen ten aanzien van beschikbaarstelling van informatie aan derden. Bijvoorbeeld het anonimiseren van datasets voorafgaand aan publicatie. Ook het gebruik van een algoritmeregister waarin is vastgelegd uit welke bronnen trainingsdata afkomstig is, kan bijdragen aan transparantie. Voorts kan gedacht worden aan het aanwijzen van een contactpersoon die door derden benaderd kan worden voor vragen.
4.5 Ontwerpfase - Outputdata
In de ontwerpfase komen er vragen aan bod per component (zie paragraaf 3). Deels zijn die vragen generiek, dus voor elk component hetzelfde, deels zijn ze componentgebonden. In deze subparagraaf worden de vragen toegelicht op het component ‘outputdata’. In sommige gevallen is het wellicht niet eens nodig om outputdata te archiveren, omdat bv. de documentatie of logica voldoende informatie biedt om aan accountability-eisen te kunnen voldoen. In dergelijke gevallen is het uiteraard niet nodig om op detailniveau deze verdiepingsvragen te doorlopen.
4.5.1 Wat? - Wat is de kwaliteit van de outputdata?
Om verantwoording af te kunnen leggen over het resultaat (outputdata) van het algoritme en het gebruik ervan, is het van belang om de kwaliteit van de data inzichtelijk te krijgen. De kwaliteit van de outputdata is in sterke mate afhankelijk van de gebruikte trainingsdata. Denk bv. aan de toetsbaarheid van de data, maar ook of het om een gereed informatieproduct gaat of om een set gegevens die gebruikt kan worden voor verdere verwerking.
4.5.2 Wat? - Wordt de outputdata gebruikt voor verdere verwerking? Zo ja, welk informatieobject wordt hiermee gecreëerd?
Onder verdere verwerking verstaan we informatieproducten waar algoritmische berekeningen aan ten grondslag liggen (bv. beleidsdocumenten). Bij dergelijke informatieproducten kun je afwegen om bijvoorbeeld beleidsdocumenten op zichzelf als outputdata te archiveren, los van het algoritme of om deze integraal te archiveren.
4.5.3 Hoe lang? - Welk impactprofiel is van toepassing?
In de ontwerpfase is deze vraag van belang om te bepalen wat de juist te treffen maatregelen zijn n.a.v. het gebruik van de outputdata. Deze afweging kun je maken o.b.v. selectielijst(en). In paragraaf 2 zijn de impactprofielen afzonderlijk beschreven.
4.5.4 Waar? - Is de opslag van outputdata noodzakelijk of volstaat de reconstructie ervan o.b.v. overige componenten?
In de ontwerpfase is deze vraag van belang voor het bepalen van de opslaglocatie. Dit is sterk afhankelijke van het interne beleid van de organisatie. Is het intern beleid om outputdata actief openbaar te maken, dan zal deze opgeslagen moeten worden op een plek van waaruit publicatie mogelijk is. Een andere afweging is of een organisatie een aangewezen archiefapplicatie heeft zoals een DMS of bijvoorbeeld een specialistische applicatie die aan een zoekmachine gekoppeld is waardoor de informatie vindbaar is voor interne belanghebbenden.
4.5.5 Waar? - Kunnen informatieproducten voor afnemende processen aansluiten op oplossingen die reeds voor het proces gebruikt zijn?
In de ontwerpfase is het van belang inzichtelijk te krijgen hoe belanghebbenden outputdata kunnen benaderen voor (her)gebruik met reeds gebruikte applicaties en systemen binnen hun processen. Denk bijvoorbeeld aan het beschikbaar stellen van outputdata via rapportagetools.
4.5.6 Waar? - Welke systemen zijn beschikbaar als mogelijke beheeromgeving?
Om te bepalen waar gegevens worden opgeslagen, moet eerst bekend zijn welke mogelijke opslaglocaties beschikbaar zijn. Denk bijvoorbeeld aan een netwerklocatie, een DMS of een datawarehouse. De uiteindelijke keuze is mede afhankelijk van de eisen en wensen die gesteld worden aan de toegankelijkheid.
4.5.7 Vorm - In welke vorm wordt outputdata beschikbaar gesteld?
In het kader van archivering en beheer is het van belang inzichtelijk te krijgen in welke vorm belanghebbenden outputdata opstellen of verwerken. Denk hierbij aan beschikbaarstelling via rapportages, dashboards, als ruwe data, mondelinge terugkoppeling via AI (spraaktechnologie) etc. De output kan bestaan uit een gereed informatieproduct dat op zichzelf gearchiveerd kan worden, maar kan ook bestaan uit een set gegevens ter verdere verwerking. In dat laatste geval zal de archivering verderop in het proces ingericht moeten worden. Bij realtime weergave in een dashboard, is er slechts een view op data en in technische zin geen outputdata. De archivering dient dan te worden geborgd via de andere componenten.
4.5.8 Beschikbaarstelling - Wie zijn de belanghebbenden van de outputdata (primaire en secundaire gebruikers, ook op de lange termijn)?
Voor de beschikbaarstelling van outputdata is het van belang om te weten hoe belanghebbenden zoeken naar informatie en in welke vorm ze die tot zich willen nemen. Op die manier kan deze op een geschikte manier worden gepresenteerd.
4.5.9 Beschikbaarstelling - Welke openbaarheidsregime is van toepassing?
Bij het beschikbaar stellen van outputdata is het van belang om relevante wet- en regelgeving (bv. WOB / WOO, AVG etc.) in acht te nemen. Dit vormt tevens de basis voor het inrichten van autorisatie.
4.5.10 Beschikbaarstelling - In welke vorm moet de outputdata beschikbaar gesteld worden aan belanghebbenden (bv. open data)?
Belanghebbenden willen informatie op verschillende wijzen gebruiken. Dat kan betekenen dat informatie op verschillende manieren ontsloten en gepresenteerd wordt. Bijvoorbeeld een vorm voor interne kennisdeling die afwijkt van een vorm voor externe publicatie.
4.5.11 Beheer - Hoe ziet het vernietigingsproces eruit?
Het ontwerpen van een vernietigingsproces gaat verder dan enkel het vaststellen van bewaartermijnen. Het gaat over het operationaliseren van de vernietiging door de processtappen te benoemen, daar actoren aan te koppelen en de verantwoordelijkheid in de organisatie te beleggen. Ook de controlemaatregelen (zoals beoordelen van een vernietigingslijst) en de mate van automatisering worden hierin meegenomen.
4.5.12 Beheer - Hoe ziet het overbrengingsproces eruit?
Als outputdata voor bewaring in aanmerking komen, dan is het zinvol om al in de ontwerpfase na te denken over overbrenging naar een archiefbewaarplaats. Richt je dit bijvoorbeeld traditioneel in: eerst verzamelen en na X jaar een gehele collectie overbrengen, via vervroegde overbrenging: bijvoorbeeld als doorlopend proces aan het eind van het kalenderjaar de relevante documenten overbrengen? De bijbehorende procesafspraken en verantwoordelijkheden kunnen aan de hand van deze keuze worden bepaald en belegd. Het is bij deze stap belangrijk om af te stemmen met de beheerder van de archiefbewaarplaats.
4.5.13 Beheer - Zijn er specifieke activiteiten te benoemen m.b.t. beschikbaarstelling aan derden (bv. bij WOB-verzoeken)?
Mogelijk is het nodig om specifieke activiteiten te benoemen en te beleggen ten aanzien van beschikbaarstelling van informatie aan derden. Bijvoorbeeld het anonimiseren van documenten voorafgaand aan publicatie. Ook het in de eigen organisatie kenbaar maken (bijvoorbeeld bij een WOB-functionaris) welke informatie er is en hoe die gevonden kan worden, draagt bij aan transparantie. Voorts kan gedacht worden aan het aanwijzen van een contactpersoon die door derden benaderd kan worden voor vragen.
4.6 Ontwerpfase - Logica
In de ontwerpfase komen er vragen aan bod per component (zie paragraaf 3). Deels zijn die vragen generiek, dus voor elk component hetzelfde, deels zijn ze componentgebonden. In deze subparagraaf worden de vragen toegelicht op het component ‘Logica’.
4.6.1 Wat - Wie is de auteur van de broncode?
De broncode (het programma waar het algoritme draait) kan open source, shared source, privaat of zelf ontwikkeld zijn. Dit heeft invloed op de wijze waarop toegankelijkheid wordt geregeld.
4.6.2 Wat - Heeft de organisatie/afdeling toegang tot de broncode?
Het kan zijn dat de organisatie/afdeling zelf geen toegang heeft tot de broncode, dit kan het geval zijn wanneer het is ontwikkeld door een commerciële partij. Het is hierbij aangeraden om een escrow contract te regelen voor wanneer deze partij stopt met het leveren van de service. Deze overeenkomst wordt gearchiveerd als onderdeel van de documentatie.
4.6.3 Wat - Ontwikkelt de broncode zich of is deze statisch?
Worden nieuwe versies van de broncode ontwikkeld en ingezet? Bij extern ontwikkelde software is het een overweging om de release notes te archiveren, wanneer er geen toegang is tot de broncode. Bij intern ontwikkelde software is de broncode beschikbaar en kan eventuele archivering intern worden georganiseerd. Hierbij kunnen release notes ook worden meegenomen.
Release notes zijn overzichtelijker en sneller te scannen/begrijpen dan broncode. In het licht van uitlegbaarheid is het archiveren van release notes een goed idee.
4.6.4 Wat - Is het datamodel statisch of dynamisch?
Wordt het datamodel verder ontwikkeld of is dit een eenmalig proces. Wanneer deze dynamisch is, met welke interval wordt deze gearchiveerd? (Elke versie, om de zoveel tijd of na zoveel veranderingen).
4.6.5 Hoe lang - Welk impactprofiel is van toepassing?
Bij de logica is deze vraag van belang om te bepalen wat de juiste te treffen maatregelen zijn n.a.v. het gebruik van de trainingsdata. Deze afweging kun je maken o.b.v. selectielijst(en). In paragraaf 2 zijn de impactprofielen afzonderlijk beschreven. Het bewaren van de logica is een van de belangrijkste componenten van dit archief.
4.6.6 Hoe lang? Volstaat het om enkel het datamodel langere tijd te bewaren en niet de broncode?
Aan de hand van het datamodel kan herleid worden op basis van welke opgegeven categorieën gegevens (bijvoorbeeld locatiegegevens, persoonsgegevens, procesgegevens) tot een de output is gekomen. Voor verantwoording kan het in sommige gevallen al voldoende zijn om dit te bewaren, zonder de daarop toegepaste rekenregels.
4.6.7 Hoe lang - Als broncode en/of datamodel zich in de loop der tijd ontwikkelen, met welke frequentie wordt er dan een nieuwe versie bewaard?
Hierbij kan gekozen worden om elke versie op te slaan, of om de zoveel tijd/versies bij grote wijzigingen.
4.6.8 Waar - Wordt de logica bij een commerciële partij opgeslagen?
Aansluitend op vraag 4.6.1. wordt de logica op dezelfde plek opgeslagen.
4.6.9 Waar - Wordt de logica intern opgeslagen?
Wanneer deze extern wordt opgeslagen/gebruikt, is het aan te bevelen hier een interne backup van te maken.
4.6.10 Vorm - In welke vorm wordt de logica opgeslagen?
De logica wordt opgeslagen in de oorspronkelijke bestandsvorm, hoe deze kan worden ingelezen door het programma. Hierbij is de voorwaarde dat het bestand ook te openen/lezen is buiten het programma. In elk geval bij een lange bewaartermijn, is het van belang om de logica in een open standaard vast te leggen.
4.6.11 Vorm - In welke vorm wordt de logica beschikbaar gesteld?
De minimale vorm van beschikbaar stellen is de bestanden als download aanbieden. Bij een uitgebreidere vorm kan gedacht worden aan een dashboard. Het is hierbij aan te raden een functionaris aan te wijzen die kennis over dit onderwerp borgt en zo eventuele vragen kan beantwoorden en indien van toepassing ontwikkelpunten kan meenemen (wanneer het algoritme nog in gebruik is).
4.6.12 Beschikbaarstelling - Wie zijn belanghebbenden van de data (primaire en secundaire gebruikers, ook op lange termijn)?
Welke partijen moeten toegang hebben tot de logica, zijn dit alleen interne gebruikers of moet deze ook voor externe beschikbaar zijn.
4.6.13 Beschikbaarstelling - Welk openbaarheidsregime is van toepassing?
Het is van belang om te weten welke eventuele beperkingen op de openbaarheid of de toegang geldend zijn.
4.6.14 Beheer - Als de broncode zich ontwikkeld: hoe wordt de gedragsmonitoring en het versiebeheer georganiseerd?
Wordt deze geautomatiseerd gearchiveerd of moet deze handmatig worden opgeslagen bij elke versie? In het eerste geval, waar wordt deze opgeslagen? In het tweede geval, wie is hiervoor verantwoordelijk?
4.6.15 Beheer - Als er een dynamisch datamodel wordt gehanteerd: hoe wordt het versiebeheer georganiseerd?
Het kan verstandig zijn een script in te stellen die bij wijziging of om de zoveel tijd een export maakt van het datamodel naar een interne (opslag)locatie.
4.6.16 Beheer - Hoe wordt nieuwe/actuele informatie toegevoegd aan de dataset?
Wie wordt hiervoor verantwoordelijk gesteld?